SPECS
- 2.9 GHz Intel Ice Lake processors across all compute nodes
- 3.0 GHz AMD Milan processors across all GPU nodes
- Infiniband HDR100 interconnect (100 Gbps)
- 919 TFLOPs Actual Performance (Rmax)
- 156 standard compute nodes (4992 total cores; 128 GB RAM per node)
- 48 mid-tier compute nodes (1536 total cores; 512 GB RAM per node)
- 7 large memory nodes (224 total cores; 1.5 TB RAM per node)
- 5 GPU nodes with 8x NVidia A100 GPUs
- 1 SXM node with 8x NVidia A100 GPUs connected via NVSwitch
- 250 TB Scratch Space
WHAT MAKES RANDI UNIQUE?
You have multiple options both on and off campus for high performance computing. Randi stands out among them for several reasons:
-
A HIPAA-compliant environment appropriate for analyzing patient data
-
Four software stacks built using both open source and commercial compilers
-
Separate software stacks for basic science and clinical research
-
GPU versions of software commonly used in the life sciences
-
The ability to handle data-intensive pipelines that require up to 1.5TB of memory
-
HPC administrators who are experts in scientific computing to help you one-on-one with optimizing your jobs, installations, and more
GET STARTED
SCIENTIFIC COMPUTING USER GROUP
Meet with the CRI scientific computing team to get the latest updates on the HPC cluster, research storage and current projects. Excess time will be used for Q&A.
Third Thursday of Every Month at 9:00 AM – 10:00 AM
GRANT LANGUAGE
Want to include CRI resources in your grant request? Use this overview provided by Anna Woodard and Hae Kyung Im.
OFFICE HOURS
Looking for assistance with using the cluster? Make an appointment during our twice-weekly office hours for help.
Every Tuesday
9:00am – 2:30pm
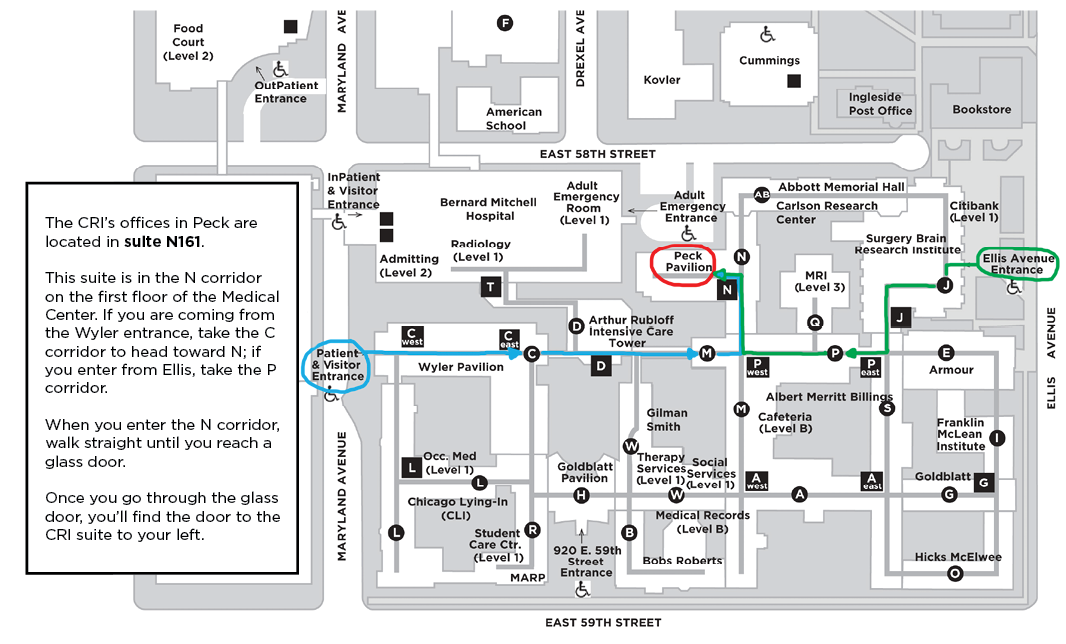
Medical Campus, Peck Pavilion Map
920 East 59th Street
Suite N161
Chicago, IL 60637
{kind=link}
FREQUENTLY ASKED QUESTIONS
Q: What credentials do I need to use the Randi cluster?
A: A BSD account or collaborator account is required to request access to CRI resources. Learn more about BSD accounts and passwords here.
Q: Are those working with basic science (non-human) data required to complete HIPAA training in order to use Randi?
A: No, HIPAA training is not required for scientists working with basic science data.
Q: How can I get technical help with Randi?
MEET OUR ASSOCIATE DIRECTOR OF SCIENTIFIC COMPUTING
Mike Jarsulic is a graduate of the University of Pittsburgh and has been with the CRI since September 2012. He previously worked at the Bettis Atomic Power Laboratory, where he was a scientific programmer focused on modernizing thermal/hydraulic design software before moving into HPC. Mike is well-versed in a variety of programming languages including Fortran, C/C++, Java, and Perl. His other interests in HPC include distributed memory programming, compiler optimizations, and long-term reproducibility of results.